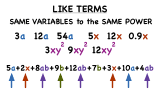Factoring Algebraic Expressions
Popular Tutorials in Factoring Algebraic Expressions
-
What are Like Terms?
Combining like terms together is a key part of simplifying mathematical expressions, so check out this tutorial to see how you can easily pick out like terms from an expression
-
How Do You Add Like Terms?
If you work with variables, you need to know how to add like variables together. This tutorial shows you exactly that! Follow along and see how to add like terms together.