How Do You Use X- and Y-Intercepts To Graph a Line In Standard Form?
Note:
To find the x-intercept of a given linear equation, simply remove the 'y' and solve for 'x'. To find the y-intercept, remove the 'x' and solve for 'y'. In this tutorial, you'll see how to find the x-intercept and the y-intercept for a given linear equation. Check it out!
Background Tutorials
-
X- and Y-Intercepts
-
What's the X-Intercept?
When you have a linear equation, the x-intercept is the point where the graph of the line crosses the x-axis. In this tutorial, learn about the x-intercept. Check it out!
-
What's the Y-Intercept?
When you have a linear equation, the y-intercept is the point where the graph of the line crosses the y-axis. In this tutorial, learn about the y-intercept. Check it out!
-
-
Ordered Pairs and The Coordinate Plane
-
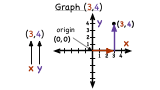
How Do You Plot Points in the Coordinate Plane?
Knowing how to plot ordered pairs is an essential part of graphing functions. In this tutorial, you'll see how to take an ordered pair and plot it on the coordinate plane. Take a look!
-
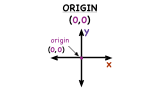
What is the Origin?
The coordinate plane has two axes: the horizontal and vertical axes. These two axes intersect one another at a point called the origin. Learn about the ordered pair that indicates the origin and its location in the coordinate plane by watching this tutorial!
-
-
Defining Linear Equations
-
What's Standard Form of a Linear Equation?
A linear equation can be written in many different forms, and each of them is quite useful! One of these is standard form. Watch this tutorial and learn the standard form for a linear equation!
-






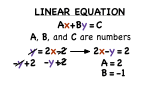

Further Exploration
-
Finding Slopes
-
How Do You Find the Slope of a Line from a Graph?
Trying to find the slope of a graphed line? First, identify two points on the line. Then, you could use these points to figure out the slope. In this tutorial, you'll see how to use two points on the line to find the change in 'y' and the change in 'x'. Then, you'll see how to take these values and calculate the slope. Check it out!
-
-
Working With Graphs
-
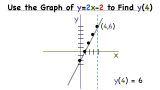
How Do You Find the Y-Coordinate of a Point on a Line If You Have a Graph?
Looking at the graph of an equation? Trying to figure out the y-value of a point on that graph? Learn how to answer that question by watching this tutorial! This tutorial shows you how to use the graph of a equation to find the y-value of a point.
-