How Do You Use Coordinates to Reflect a Figure Over the X-Axis?
Note:
Want to see how to reflect a figure over the x-axis? Then this tutorial was made for you! In this tutorial, you'll see how to use coordinates from the original figure to reflect the figure over the x-axis. Take a look!
Background Tutorials
-
Use a pair of perpendicular number lines, called axes, to define a coordinate system, with the intersection of the lines (the origin) arranged to coincide with the 0 on each line and a given point in the plane located by using an ordered pair of numbers, called its coordinates. Understand that the first number indicates how far to travel from the origin in the direction of one axis, and the second number indicates how far to travel in the direction of the second axis, with the convention that the names of the two axes and the coordinates correspond (e.g., x-axis and x-coordinate, y-axis and y-coordinate).
-
What is the X-Coordinate?
Ordered pairs are a crucial part of graphing, but you need to know how to identify the coordinates in an ordered pair if you're going to plot it on a coordinate plane. In this tutorial, you'll see how to identify the x-coordinate in an ordered pair!
-
What is the Y-Coordinate?
Ordered pairs are a crucial part of graphing, but you need to know how to identify the coordinates in an ordered pair if you're going to plot it on a coordinate plane. In this tutorial, you'll see how to identify the y-coordinate in an ordered pair!
-
-
Lines are taken to lines, and line segments to line segments of the same length.
-
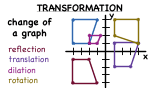
What is a Transformation?
Transformations can be really fun! They allow you to change or move a figure. In this tutorial, learn about all the different kinds of transformations!
-
-
Understand that a two-dimensional figure is congruent to another if the second can be obtained from the first by a sequence of rotations, reflections, and translations; given two congruent figures, describe a sequence that exhibits the congruence between them.
-
What is a Reflection?
When you look in the mirror, you see your reflection. In math, you can create mirror images of figures by reflecting them over a given line. This tutorial introduces you to reflections and shows you some examples of reflections. Take a look!
-
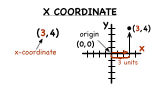

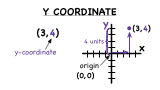


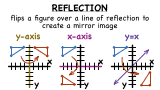

Further Exploration
-
Describe the effect of dilations, translations, rotations, and reflections on two-dimensional figures using coordinates.
-
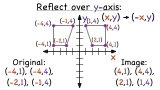
How Do You Use Coordinates to Reflect a Figure Over the Y-Axis?
Want to see how to reflect a figure over the y-axis? Then this tutorial was made for you! In this tutorial, you'll see how to use coordinates from the original figure to reflect the figure over the y-axis. Take a look!
-